Apache Kafka: The Backbone of Real-Time Data Streaming

Learn how Apache Kafka enables real-time data streaming, microservices, and event-driven architectures
Introduction
Imagine you’re booking a ride on Uber. The app instantly matches you with a driver, calculates ETA, and updates both your and the driver’s screens in real-time. How does this happen so fast?
The answer lies in Apache Kafka—a high-performance, distributed event streaming platform. Whether it's financial transactions, e-commerce order tracking, or real-time analytics, Kafka is the engine that powers them all.
In this blog, we’ll break down what Kafka is, how it works, real-world use cases, and code examples to help you get started.
What is Apache Kafka?
Apache Kafka is an open-source distributed system for real-time event streaming, data processing, and messaging. It allows different systems to send and receive messages at massive scale and ultra-low latency.
💡 In simple terms: Kafka is like a high-speed message broker that connects applications and helps them communicate efficiently.
Why is Kafka so popular?
✅ Scalable: Handles millions of messages per second.
✅ Fault-Tolerant: Replicates data across multiple nodes.
✅ Real-Time Processing: Enables event-driven architectures.
✅ High Throughput: Optimized for large-scale data pipelines.
✅ Decouples Microservices: Enables loosely coupled applications.
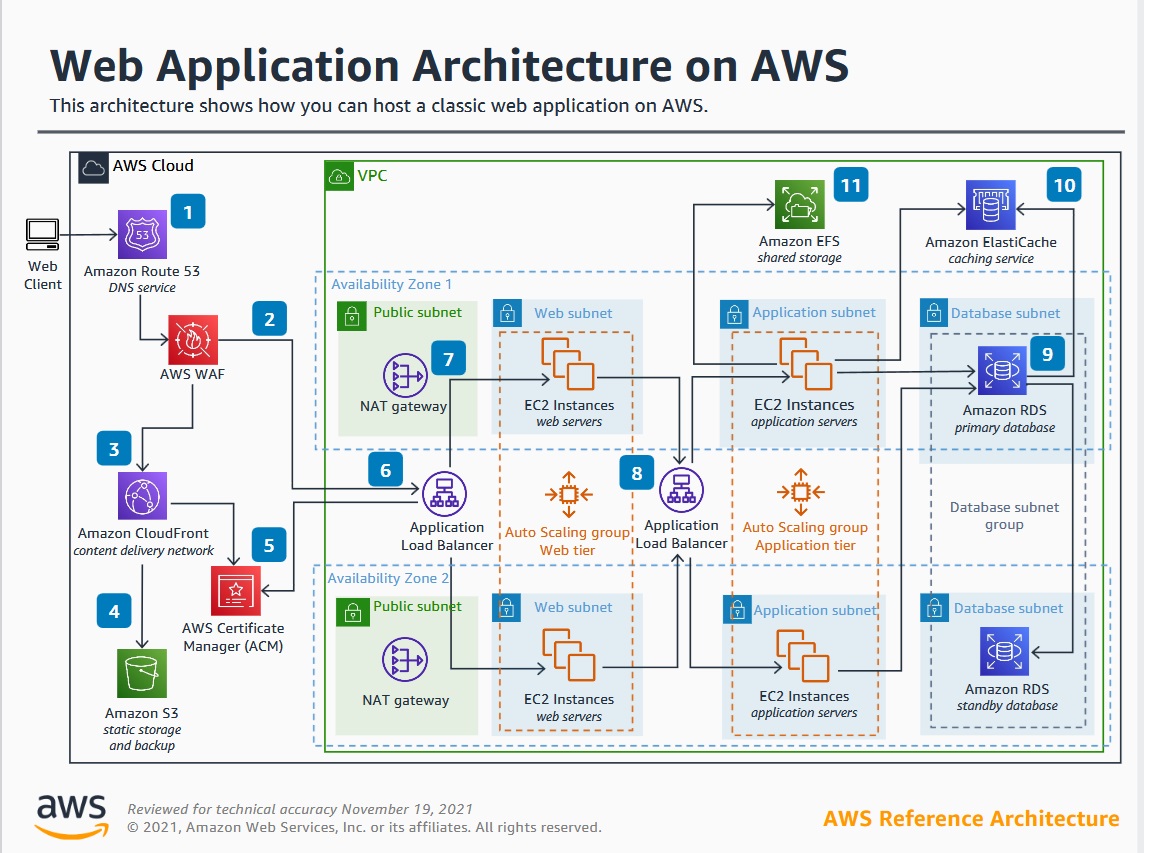
Apache Kafka Architecture & Components
Kafka works in a publish-subscribe model, where Producers send messages, Consumers receive them, and everything is stored in a distributed log.
Kafka Architecture Diagram
┌───────────┐
│ Producer │
└───────────┘
│
┌────────▼────────┐
│ Topic │
├────────┬────────┤
Partition 0 Partition 1 Partition 2
┌───────┐ ┌───────┐ ┌───────┐
│Broker │ │Broker │ │Broker │
└───────┘ └───────┘ └───────┘
│ │ │
┌──────▼─────┐ ┌────▼──────┐ ┌──▼───────┐
│ Consumer A │ │ Consumer B │ │ Consumer C │
└───────────┘ └───────────┘ └───────────┘
Here’s how Kafka is structured:
1. Producer (Message Sender)
Generates data and sends it to Kafka topics.
Example: A sensor sending temperature data.
2. Topic (Message Category)
A logical group for messages (like an email folder).
Topics are partitioned for parallel processing.
3. Partition (Scalability Unit)
A topic is split into multiple partitions for efficiency.
Messages are distributed across partitions for load balancing.
4. Broker (Storage & Routing)
A Kafka broker stores messages and delivers them to consumers.
Kafka clusters usually have multiple brokers.
5. Consumer (Message Receiver)
Reads messages from topics.
Consumer Groups allow multiple consumers to share workload.
6. ZooKeeper (Cluster Manager)
Manages metadata, leader elections, and cluster health.
Future versions of Kafka will replace ZooKeeper with KRaft.
1. Install Kafka Locally
Kafka requires Java. Check your Java version:
java -version If Java isn’t installed, install OpenJDK:
sudo apt update && sudo apt install openjdk-11-jdk -y Download Kafka and extract it:
wget https://downloads.apache.org/kafka/3.4.0/kafka_2.13-3.4.0.tgz tar -xvzf kafka_2.13-3.4.0.tgz cd kafka_2.13-3.4.0 2. Start Kafka & ZooKeeper
Start ZooKeeper (Kafka requires it):
bin/zookeeper-server-start.sh config/zookeeper.propertiesStart Kafka Broker:
bin/kafka-server-start.sh config/server.properties3. Create a Kafka Topic
bin/kafka-topics.sh --create --topic test-topic --bootstrap-server localhost:9092 --partitions 3 --replication-factor 1 4. Start a Kafka Producer
Run a producer to send messages:
bin/kafka-console-producer.sh --topic test-topic --bootstrap-server localhost:9092 Type a message and hit Enter
Hello, Kafka! 5. Start a Kafka Consumer
Run a consumer to receive messages:
bin/kafka-console-consumer.sh --topic test-topic --from-beginning --bootstrap-server localhost:9092You should see:
Hello, Kafka!🎉 Congrats! You just set up a working Kafka pipeline!